
Вступление
В предыдущей статье мы с вами поговорили о RNN — прекрасной архитектуре, но все-таки с некоторыми минусами. И сегодня мы рассмотрим альтернативную архитектуру — трансформеры. Эта инновационная архитектура актуальна вследствие нескольких проблем RNN:
- Во-первых, RNN содержат всю информацию о последовательности в скрытом состоянии, которое обновляется с каждым шагом. Если модели необходимо “вспомнить” что-то, что было сотни шагов назад, то эту информацию необходимо хранить отдельно . Следовательно, придется иметь либо очень большое скрытое состояние, либо мириться с потерей информации.
- Во-вторых обучение рекуррентных сетей сложно распараллелить: чтобы получить скрытое состояние RNN-слоя для шага i+1, необходимо вычислить состояние для шага i
Механизм внимания
Уникальная особенность трансформеров, позволяющая нам справиться с этой проблемой — “механизм внимания”. “Механизм внимания” основывается на трех сущностях: “Запросы” (Q, Что я ищу?), “Ключи” (K, Как я могу быть описан?) и “Значения” (V, Какую информацию я несу?). Механизм вычисляет, насколько каждый запрос соответствует каждому ключу, получая веса внимания, которые показывают степень важности других слов. Затем эти веса используются для построения взвешенной суммы их значений, создавая представление слова, отражающее контекст.
Чтобы разобраться, давайте обратимся к математической формуле внимания. Внимание(Q, K, V) = Softmax((Q * K^T) / scale) * V., где Q * K^T — шаг сравнения, Softmax(…) — функция активации, о которой мы говорили в предыдущих статьях (нормализация), * V — взвешенное суммирование смыслов (шаг извлечения контекста).
Multi-Head Attention
Однако, одного механизма внимания мало. Ведь бывают сложные предложения, с разнообразными связями между словами. Чтобы выявлять их все одновременно, трансформер использует Multi-Head Attention. Этот механизм можно сравнить с работой команды, где каждый участник работает со своей специализацией. Например, первый участник ищет связи между субъектом и действием, второй между действием и объектом, а третий — логические связи. Таким образом, multi-head attention позволяет выявлять разные типы связей в данных, применяется: параллельно запускаются несколько блоков внимания с разными параметрами, а их результаты объединяются.
Таким образом, трансформер состоит из следующих слоев энкодер (для анализа) и декодер (для генерации), каждый из которых состоит из следующих блоков: слой эмбеддинга, multi-head attention, полносвязная нейросеть, остаточные связи (для перебрасывания информации между слоями нейросети), и нормализация. Если вам что-то из этих слоев кажется незнакомым — посмотрите предыдущие статьи, чтобы углубиться в устройство нейронных сетей.
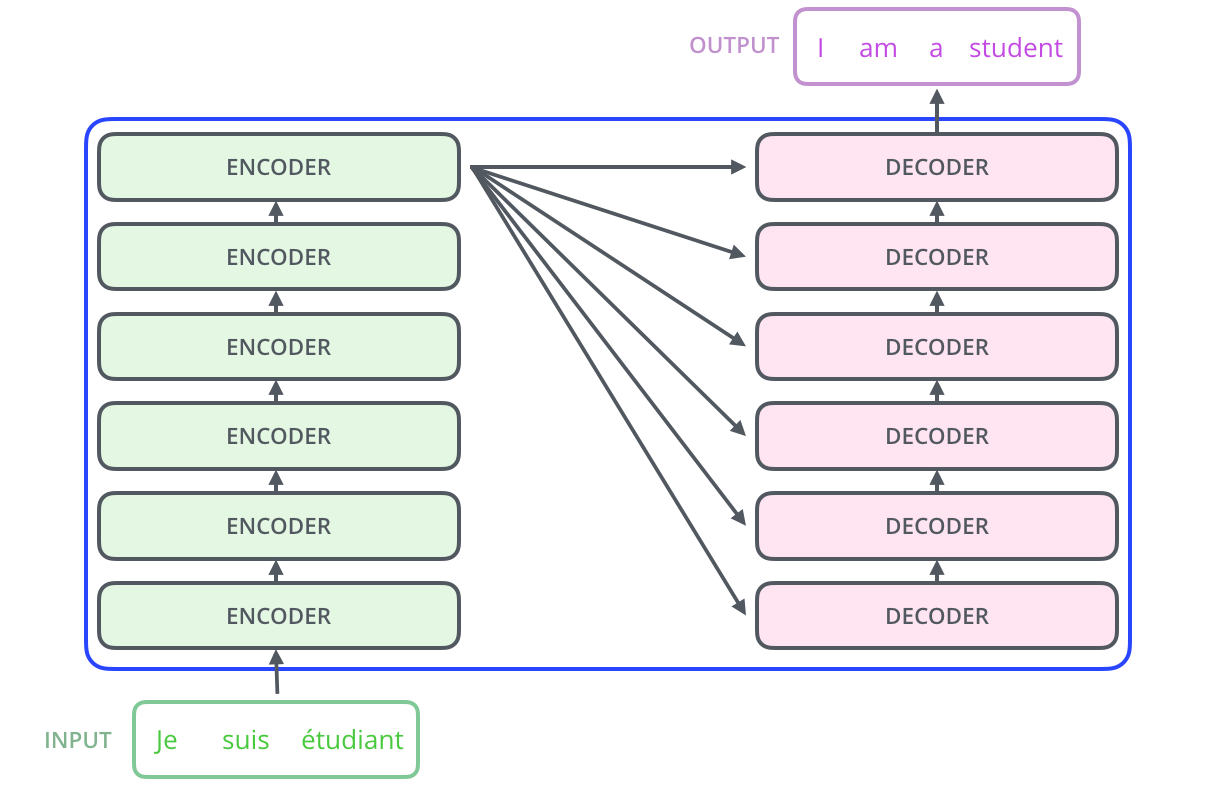
Хоть трансформеры изначально были разработаны для обработки текста, они успешно применяются и в других сферах, например для анализа изображений или генерации.
Источники:
- Эпоха ИИ-трансформеров: что это за архитектура и как работает механизм внимания // serverflow.ru URL: https://serverflow.ru/blog/stati/epokha-ii-transformerov-chto-eto-za-arkhitektura-i-kak-rabotaet-mekhanizm-vnimaniya/
- Трансформер // neerc.ifmo.ru URL: https://neerc.ifmo.ru/wiki/index.php?title=Трансформер
- Трансформеры // education.yandex.ru URL: https://education.yandex.ru/handbook/ml/article/transformery
Информация о произведении:
Автор: Вероника Алексеенко-Недышилова
Редакторы: Сабуров Даниил и Марк Ершов
Условия использования: свободное некоммерческое использование при условии указания автора и ссылки на первоисточник.
Для коммерческого использования — обращаться на почту: buildxxvek@gmail.com